正则在Java中的基本使用
什么是正则?
正则表达式,是一种用于描述字符串匹配规则的表达式。通过正则表达式可以字符串中找到符合特定规则的内容。正则表达式就像是一把强大的查找和替换工具,但更加灵活。
为什么需要正则?
在网站的开发之中,经常需要接触的就是对于表单的操作,比如:邮箱的验证、手机号的验证。为了保证这些数据的正确性,我们都需要对数据进行一些复杂的验证处理。在此我们以Java语言为例,判断是否是一个邮箱格式。
1 | public static boolean isValidEmail(String email) { |
以上的代码,我们实现了一个基本邮箱格式的判断。但代码有点过于复杂了,如果使用正则来验证会不会比较简单呢?下面是一个正则验证邮箱的格式的例子。
1 | private static boolean isValidEmail(String email) { |
通过上面的例子我们发现,使用正则来验证数据的格式,将会变得简单很多。这也是正则最大的特点。
常用正则标记
- 基本字符匹配:
. | 匹配除换行符外的任意字符。 | 示例:a.b 可以匹配 “aab”、“aeb”、“acb” 等。 |
|---|---|---|
[] | 字符集,匹配方括号中的任意一个字符。 | 示例:[aeiou] 可以匹配任何一个元音字母。 |
[^] | 否定字符集,匹配除方括号中字符外的任意一个字符。 | 示例:[^0-9] 可以匹配任何非数字字符。 |
\d | 匹配任意数字字符,相当于 [0-9]。 | |
\D | 匹配任意非数字字符,相当于 [^0-9]。 | |
\w | 匹配任意字母、数字或下划线字符,相当于 [a-zA-Z0-9_]。 | |
\W | 匹配任意非字母、数字或下划线字符,相当于 [^a-zA-Z0-9_]。 | |
\s | 匹配任意空白字符,包括空格、制表符、换行符等。 | |
\S | 匹配任意非空白字符。 |
- 重复匹配:
* | 匹配前一个元素零次或多次。 | 示例:ab*c 可以匹配 “ac”、“abc”、“abbc” 等。 |
|---|---|---|
+ | 匹配前一个元素一次或多次。 | 示例:ab+c 可以匹配 “abc”、“abbc” 等,但不能匹配 “ac”。 |
? | 匹配前一个元素零次或一次。 | 示例:ab?c 可以匹配 “ac”、“abc”,但不能匹配 “abbc”。 |
- 位置匹配:
^ | 匹配字符串的开始。 | 示例:^abc 可以匹配以 “abc” 开头的字符串。 |
|---|---|---|
$ | 匹配字符串的结束。 | 示例:xyz$ 可以匹配以 “xyz” 结尾的字符串。 |
- 特殊字符匹配:
\ | 转义字符,使其后的字符失去特殊含义。 | 示例:\d 匹配任意数字字符。 |
|---|
- 分组和引用:
() | 用于将多个元素分组。 | 示例:(abc)+ 可以匹配 “abc”、“abcabc” 等。 |
|---|---|---|
\n | 引用前面的第n个分组匹配到的文本。 | 示例:(\d{2})-(\d{2})-(\d{4}) 可以匹配日期形式,如 “01-01-2022”,并通过引用获取年、月、日。 |
- 边界匹配:
\b | 匹配单词的边界。 | 示例:\bword\b 可以匹配 “word”,但不匹配 “words” 或 “password”。 |
|---|---|---|
\B | 匹配非单词边界。 |
- 量词:
| {n} | 匹配前一个元素恰好n次。 | 示例:a{3} 可以匹配 “aaa”。 |
|---|---|---|
{n,} | 匹配前一个元素至少n次。 | |
{n,m} | 匹配前一个元素至少n次,最多m次。 |
常用正则
匹配邮箱地址:
1
^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}$
匹配URL:
1
^(https?|ftp):\/\/[^\s/$.?#].[^\s]*$
匹配日期:
1
^\d{4}-\d{2}-\d{2}$
匹配手机号码:
1
^\d{11}$
匹配身份证号码:
1
^(^\d{17}(\d|X|x))$
匹配IP地址:
1
^(?:[0-9]{1,3}\.){3}[0-9]{1,3}$
匹配用户名(字母开头,允许字母数字下划线,长度6-20):
1
^[a-zA-Z][a-zA-Z0-9_]{5,19}$
匹配密码(包含大小写字母和数字,长度8-16):
1
^(?=.*[a-z])(?=.*[A-Z])(?=.*\d)[a-zA-Z\d]{8,16}$
匹配 HTML 标签:
1
<[^>]+>
匹配中文字符:
1
[\u4e00-\u9fa5]
正则处理类
Pattern:正则表达式编译;
1
2// 将给定的正则表达式编译为模式。
public static Pattern compile(String regex)- 正则拆分
1
2// 将给定的输入分成这个规则的匹配。
public String[] split(CharSequence input)示例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21public static void main(String[] args) {
// 要拆分的字符串
String inputString = "apple,orange,banana,grape";
// 使用逗号作为分隔符进行拆分
String[] fruits = splitString(inputString, ",");
// 输出拆分后的结果
System.out.println("拆分后的水果:");
for (String fruit : fruits) {
System.out.println(fruit);
}
}
public static String[] splitString(String input, String delimiter) {
// 构建正则表达式
String regex = Pattern.quote(delimiter);
// 使用正则表达式拆分字符串
return input.split(regex);
}Matcher:正则表达式匹配,实现了正则表达式的处理类,对象的实例化依靠Pattern类完成;
- 获取matcher对象
1
2// 获取matcher对象
public Matcher matcher(CharSequence input)- 正则表达式匹配
1
public static boolean matches(String regex,CharSequence input)
示例:
1 | public static void main(String[] args) { |
正则分组
正则表达式中的分组是用括号
()包围的部分,可以用来实现匹配的分组操作。
示例:
1 | String sql = "INSERT INTO dept(deptno, dname, loc) VALUES(#{deptno}, #{dname}, #{loc})"; |
自动生成正则
如果记不住那些复杂的正则标记,有没有办法可以根据我们的提供的需求,自动生成正则表达式呢?当然是可以的。那么你可以使用ChatGPT大语言模型,来根据我们的提供的需求自动帮我们生成正则,甚至可以可以帮我写好样例代码,拿来用就好了。

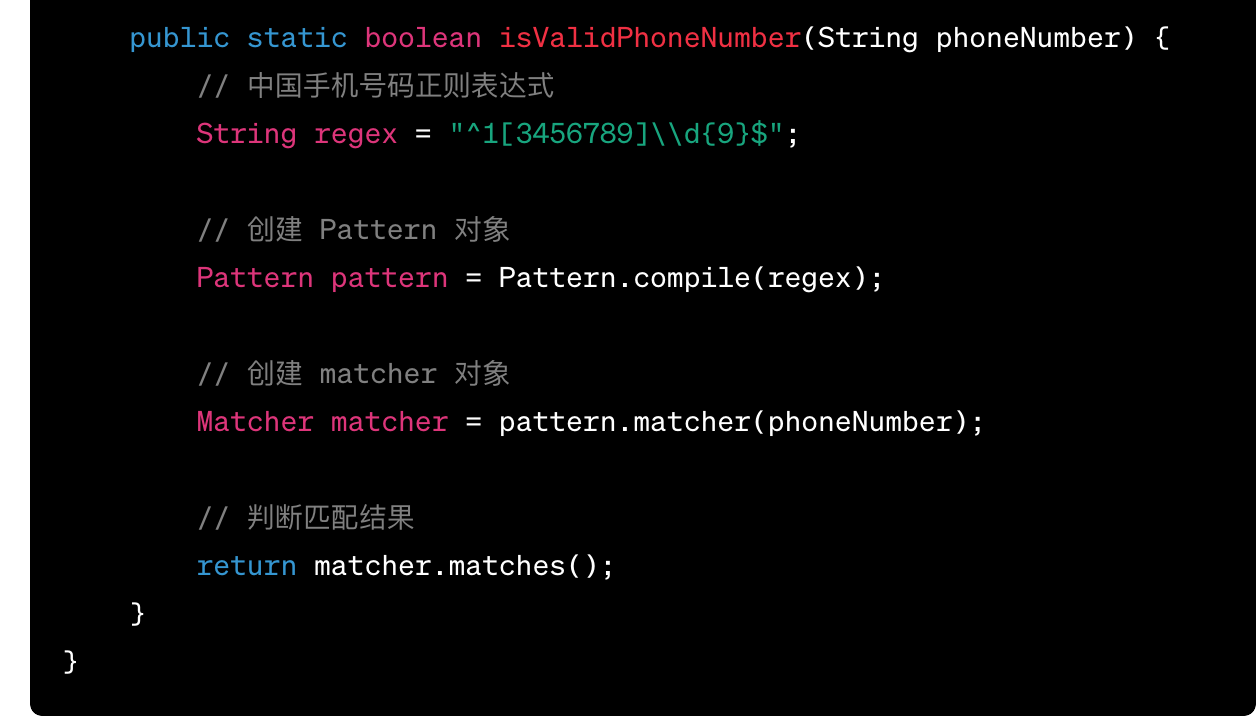

代码、注释、说明都给了很清晰的说明,简直太贴心了。